Feed Forward Neural Network Language Model
- 기계가 자연어를 표현하도록 규칙으로 명세하기 어려운 상황에서 규칙 기반 접근이 아닌 기계가 주어진 자연어 데이터를 학습하게 하는 것 ⇒ 인공 신경망 이용
- 신경망 언어 모델의 시초. 간단히 줄여 NNLM
N-gram 언어 모델의 한계
- 언어 모델은 문장에 확률을 할당하는 모델
- 즉, 주어진 문맥으로부터 아직 모르는 단어를 예측하는 것을 언어 모델링이라고 한다고 N-gram에서 배웠다.
※ 다음 단어 예측하기
An adorable little boy is spreading __
- 위 문장을 가지고 N-gram 언어 모델이 언어 모델링을 하는 방법은 n-1개의 단어를 참고하여 확률에 기반하여 예측한다.
$$ P(w|boy\; is \; spreading) = \frac{count(boy\;is\;spreading\;w)}{count(boy\;is\;spreading)} $$
- 이러한 언어 모델은 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링하지 못하는 희소 문제-Sparsity problem-가 생긴다.
- 훈련 코퍼스에 ‘boy is spreading smile’라는 단어 시퀀스가 존재하지 않으면 n-gram 언어 모델에서 해당 단어 시퀀스의 확률 $P(Smiles|boy\;is\;spreading) = 0$이 된다.
단어의 의미적 유사성
- 희소 문제는 기계가 단어의 의미적 유사성을 알 수 있다면 해결할 수 있는 문제이다.
- 예를 들어보자. ‘톺아보다’라는 생소한 단어가 있다. ‘샅샅이 살펴보다’와 유사한 의미이다. 만약, ‘발표 자료를 살펴보다’라는 단어 시퀀스는 존재하지만, ‘발펴 자료를 톺아보다’라는 단어 시퀀스는 존재하지 않는 코퍼스를 학습한 언어 모델이 있다고 가정하자. 언어 모델은 아래 선택지에서 다음 단어를 선택해야 한다.

- 우리는 지금 ‘톺아보다’와 ‘살펴보다’의 의미적 유사성을 알았기 때문에 두 선택지 중에서 ‘톺아보다’가 더 맞는 선택이라고 판단할 수 있다. 하지만, n-gram 언어 모델은 ‘톺아보다’의 확률을 0으로 계산하기 때문에 ‘톺아보다’를 선택할 수 없다.
- 만약 언어 모델 또한 단어의 의미적 유사성을 학습할 수 있도록 설계한다면, 훈련 코퍼스에 없는 단어 시퀀스에 대한 예측이라도 유사한 단어가 사용된 단어 시퀀스를 참고하여 보다 정확한 예측을 할 수 있다.
- 바로! 이러한 아이디어를 반영한 언어 모델이 신경망 언어 모델 NNLM이다.
- 그리고 이 아이디어는 단어 벡터 간 유사도를 구할 수 있는 벡터를 얻어내는 워드 임베딩(word embedding)의 아이디어 이기도 하다.
- 그렇다면 NNLM이 어떻게 훈련 과정에서 단어의 유사도를 학습할 수 있는지 알아보자
NNLM의 학습 과정
예문 : “what will the fat cat sit on”
- 훈련 코퍼스에 위와 같은 문장이 있다. 훈련 과정에서 ‘what will the fat cat’이라는 단어 시퀀스가 입력으로 주어지면, 다음 단어 ‘sit’을 예측하는 방식으로 훈련된다.
- 'what will the fat cat'를 입력을 받아서 'sit'을 예측하는 일은 기계에게 what, will, the, fat, cat의 원-핫 벡터를 입력받아 sit의 원-핫 벡터를 예측하는 문제
1. 훈련 코퍼스가 준비된 상태에서 가장 먼저 해야할 일 → 기계가 단어를 인식할 수 있도록 모든 단어를 수치화 하는 것. (여기서는 훈련 코퍼스에 7개의 단어만 존재한다고 가정)
- what = [1, 0, 0, 0, 0, 0, 0]
- will = [0, 1, 0, 0, 0, 0, 0]
- the = [0, 0, 1, 0, 0, 0, 0]
- fat = [0, 0, 0, 1, 0, 0, 0]
- cat = [0, 0, 0, 0, 1, 0, 0]
- sit = [0, 0, 0, 0, 0, 1, 0]
- on = [0, 0, 0, 0, 0, 0, 1]
2. NNLM은 n-gram 언어 모델처럼 다음 단어를 예측할 때, 앞의 모든 단어를 참고하는 것이 아니라 정해진 개수의 단어만을 참고한다. (여기서는 n을 4라고 해보자) → 이 범위를 윈도우라고 표현하기도 한다. 윈도우의 크기 = 4
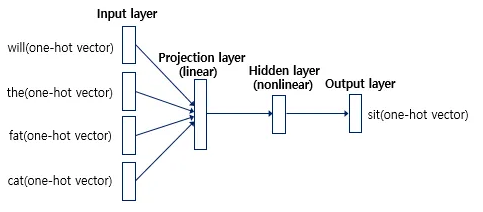
3. 윈도우의 크기를 4로 정하였으므로 ‘will, the, fat, cat’의 원-핫 벡터가 입력으로 들어간다.
4. output layer를 보면 모델이 예측한 값의 오차를 구하기 위해 레이블로 sit이 one-hot vector로 사용된다.
5. Projection Layer : 4개의 one-hot vector를 입력 받은 NNLM은 다음층인 투사층을 지나게 된다. 인공 신경망에서 입력층과 출력층 사이의 층은 보통 은닉층이라고 부르는데, 여기서 투사층이라고 명명한 이 층은 일반 은닉층과 다르게 가중치 행렬과의 곱셈은 이루어지지만 활성화 함수가 존재하지 않는다. 여기서 투사층의 크기를 M이라고 해보자.
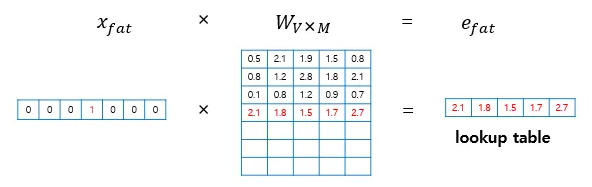
- 각 입력 단어들은 투사층에서 V × M 크기의 가중치 행렬과 곱해진다. 여기서 V는 단어 집합의 크기를 의미한다. 만약 원-핫 벡터의 차원이 7이고, M이 5라면 가중치 행렬 W는 7 × 5 행렬이 된다.
- 각 단어의 원-핫 벡터와 가중치 W 행렬의 곱이 어떻게 이루어지는지 봐보자. 원-핫 벡터의 특성으로 인해 i번째 인덱스에 1이라는 값을 가지고 그 외의 0의 값을 가지는 원-핫 벡터와 가중치 W 행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과-lookup- 동일하다. 그래서 이 작업을 룩업 테이블-lookup table-이라고 한다.
6. 룩업 테이블 후에는 V차원을 가지는 one-hot vector는 이보다 더 차원이 작은 M차원의 벡터로 mapping. 위 그림에서 단어 fat을 의미하는 원-핫 벡터를 x_{fat} 으로 표현했고, 테이블 룩업 과정을 거친 후의 단어 벡터는 e_{fat} 으로 표현했다. 이 벡터들은 초기에는 랜덤한 값을 가지지만 학습 과정에서 값이 계속 변경되는데 이 단어 벡터를 임베딩 벡터-embedding vector-라고 한다.
7. 각 단어가 테이블 룩업을 통해 임베딩 벡터로 변경되고, 투사층에서 모든 임베딩 벡터들의 값은 연결됩니다(”concatenate” 이후 벡터를 concatenate한다는 표현은 연결한다는 표현. 더하는 것이 아니다! ).
가령, 5차원 벡터 4개를 연결한다는 의미는 20차원 벡터를 얻는다는 의미.
- x를 각 단어의 원-핫 벡터, NNLM이 예측하고자 하는 단어가 문장에서 t번째 단어라고 하고, 윈도우의 크기를 n , 룩업 테이블을 의미하는 함수를 lookup , 세미콜론(;)을 연결 기호로 하였을 때 투사층을 식으로 표현하면 아래와 같다.
$$p^{layer}=(lookup(x_{t-n});\dots;lookup(x_{t-2});lookup(x_{t-1})) = (e_{t-n};\dots;e_{t-2};e_{t-1})$$
- 이 층은 선형층이다! 활성화 함수 사용하지 않는다.
8. 이 후 부터는 우리가 알던 인공 신경망 구조와 비슷하다. 은닉층의 가중치와 곱해진 후 bias와 더하고 활성화 함수의 입력으로 들어간다. 이때의 가중치와 편향을 W_h, b_h라고 하고, 은닉층의 할성화 함수를 하이퍼볼릭탄젠트를 썼을 때 식은 다음과 같다.
$$h^{layer}=tanh(w_hp^{layer}+b_h)$$
9. 이렇게 은닉층을 거쳐 출력층으로 향하며 출력은 V차원의 벡터가 된다. 출력층에서 활성화 함수로 softmax를 사용하여 예측 확률로 사용할 수 있다.
$$\hat{y}=softmax(w_yh^{layer}+b_y)$$
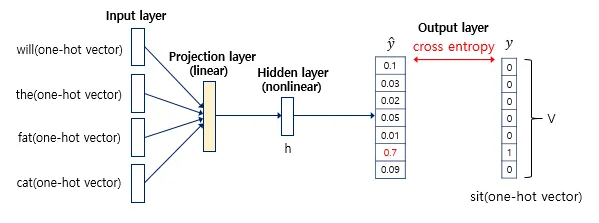
10. 출력 벡터의 각 차원 안에서의 값이 의미하는 것은 다음과 같다. \hat{y}의 j번째 인덱스가 가진 0과 1 사이의 값은 j번째 단어가 다음 단어일 확률을 나타낸다. 즉, 실제 y의 값에 가까워져야 한다.
※ 그렇다면 이 때 쓰일 손실 함수는? 당연히 cross-entropy 함수를 사용해야 한다. (-Cross entroy-가 궁금하다면 손실함수 부분 참고) 어떻게 보면 모든 단어 V개의 선택지 중에서 정답인 ‘sit’을 예측해야 하는 다중 클래스 분류 문제이다.
임베딩 벡터? 유사성?
- NNLM에서 중요한 점은, 투사층의 가중치 행렬도 backpropagation 과정에서 학습되기 때문에 단어 임베딩 벡터 또한 함께 학습되는 것이 중요하다.
- NNLM의 핵심은 충분한 양의 훈련 코퍼스를 위와 같은 과정으로 학습한다면 결과적으로 수많은 문장에서 유사한 목적으로 사용되는 단어들은 결국 유사한 임베딩 벡터 값을 얻게 된다.
- 이 결과 훈련 코퍼스에 없던 새로운 문장에서도 비슷한 단어를 유추할 수 있는 능력을 갖게 된다!
핵심
1. 단어를 표현하기 위해 임베딩 벡터를 사용하므로 단어의 유사도를 계산할 수 있게 되었다. 이것은 희소 문제를 어느정도 해결할 수 있었다.
2. 하지만 고정된 길이의 입력-Fixed-length input-의 한계는 극복하지 못했다. N-gram과 마찬가지로 다음 단어를 예측하기 위해 모든 이전 단어를 참고하는 것이 아니라 정해진 n개의 단어만을 참고할 수 있었다. 이것을 극복한 것은? RNNLM
'ALL About NLP & LLM' 카테고리의 다른 글
| N-gram (0) | 2025.03.04 |
|---|